Microtargeting and analytics tools are ubiquitous in many campaigns, and there is no shortage of vendors willing to sell candidates models to better target their communication. But are more, and more tailored, tools always worth the investment? In many instances the answer is an emphatic “yes,” but in others campaigns need to carefully consider existing generic resources and decide if tailored models are necessary.
Just this year, we worked on a school board race in which one of our opponents diverted resources from their voter contact program to pay someone to help them “microtarget” their mail. Campaign staff are now socialized to expect the most advanced analytics tools available to campaigns regardless of whether those tools can be fully justified. This expectation means we have seen countless cases where scarce resources are used to target, rather than communicate with, voters.
There is no question that analytic tools are vital and useful for modern campaigns. We were building and evangelizing such tools before it was in vogue to do so and believe in their value, but there is also no question that campaigns must always think critically about whether the investment in such tools is worthwhile.
The reality is that new analytics tools are not necessarily a valuable investment for campaigns that already have access to other resources that are great, or even resources that may be described by the eminent political guru Larry David as “pretty, pretty good.”
The question that always needs to be asked when assessing the value of a new tool is “compared to what?”. Even the worst campaigns don’t find targets by sticking pins in phonebooks, they use voterfile selects (vote history, partisan registration, basic demographics), or existing microtargeting tools that come with their voterfiles.
The problem is that too frequently the metrics used to assess new models, whether they be r-squareds, ROC analyses or other statistical tests, are comparing performance to random chance. The real way we should think about the value of new analytics resources is by asking the questions “how much better and different would our targeting be with a new tool, compared to how we would have found targets using existing free resources?”. These free resources may be voterfile selects or existing models, which on most voterfiles are often amazingly powerful.
New tools may make targeting better, but often only marginally better. Before a dollar is taken away from communicating with voters to decide how to target them, a full understanding needs to be made of whether that marginal increase in efficiency is worthwhile.
The calculation of whether it is worthwhile will depend on three main factors:
- The cost of the new analytics tool.
- How different you expect the targeting using new tools to be compared to existing tools.
- How much communication is going to be driven by the targeting.
In 2017, voterfile vendors and committees are producing generic turnout, partisan, and issue models that are available as part of voterfile subscriptions that can greatly enhance targeting by campaigns.
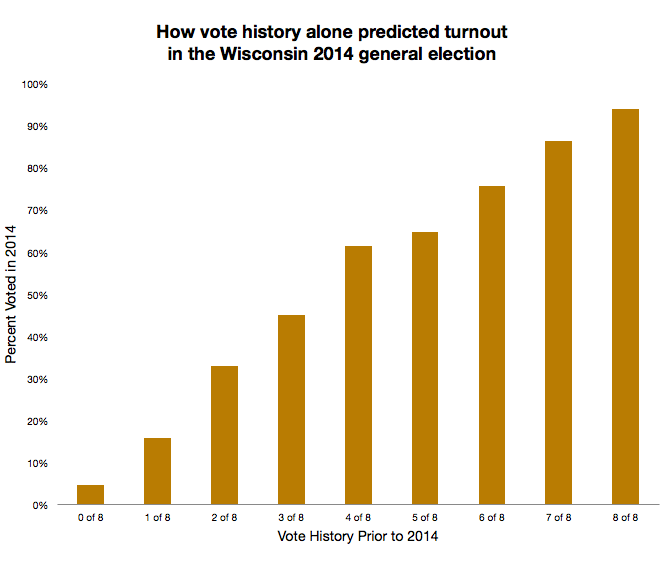
In addition, it must be noted that the key variables that drive these existing generic models will also likely be the same key variables that drive whatever new custom models are created. And for good reason. As shown in the chart. The single biggest predictor of whether someone will vote is their prior vote history. Even without accounting for when people are eligible to vote in given elections, knowing people’s vote history is a really efficient way of finding likely voters. Adding in additional information (registration date, age, gender as well as other commercial data such as marital status, whether they rent or own a home) can give more nuanced, accurate targets, but even the best turnout models point to overwhelmingly the same targets as vote history selects.
Similarly, generic nationally built turnout models will have even more overlap with a district specific model, but the difference will be marginal. How big that difference will be will depend on a lot of factors such as whether the state has atypical turnout rates (often because of atypical access or barriers to the polls), whether there are meaningful elections in odd numbered years, or whether the context of the election is dramatically different in a given year. All these characteristics can make a difference, but the driving factors in most models will still be the same, and the targets identified by most models predicting equivalent traits will largely be the same.
Even for support models, especially in states with partisan registration or a strong reservoir of historic IDs, partisan and candidate support models will be driven by the same key variables and the targets they suggest will largely be the same people. There will of course be differences, especially when a candidate (or opponent) has a major demographic of support, or appeals far beyond a more “generic” candidate, or if there is a major change in the political landscape, but such differences are at the margins.
There are lots of cases where tailored models are without doubt worth the investment. Most importantly this will be the case when the trait that you are trying to predict is different to available resources or the political landscape has shifted from when existing resources were created. A model predicting support for an anti-choice, pro-gun Democrat may be dramatically different to a generic partisan model; a model predicting positions on marriage equality or marijuana legalization may be dramatically different to a model predicting other progressive values; or a model predicting turnout in a state with a history of odd-year or major special elections may give dramatically different targets compared to other turnout models. An understanding of the underlying politics, and testing existing resources against any available polling or IDs will help give real insights of when custom modelling is most likely to have the greatest impact and fully justify its cost.
Related to this is the irony that hard political and data contexts can create models that perform less well on statistical tests (compared to random selects) that often are far more valuable to campaigns. A candidate specific support model in a party-registration state with a long history of collecting IDs may ooze in statistical power, but will likely be very similar to a generic partisan model, or candidate model for a different candidate in the state. In contrast, a candidate support model in a state without partisan registration, and lacking demographic diversity (such as North Dakota or Wisconsin) may not reach anywhere near the level of statistical power, but could be far more valuable compared to a generic partisan model. This is because the generic and specific models are less likely to have the same inputs that account for the vast majority of the variance and so factors that may be more specific to candidates may differentiate the models more.
Beyond the nuances of different situations, the most important thing to have in mind when deciding whether to invest in analytic tools is this simple rule: spreadsheets don’t win votes, communicating with voters wins votes. Unless the spreadsheet can dramatically increase the efficiency of the communication, or the communication budget dwarfs the cost of the tools, the resources should be focused on the voters. Targeting voters isn’t enough. You have to communicate with them, and in a world of scarce resources we need to be careful about how we allocate them.